
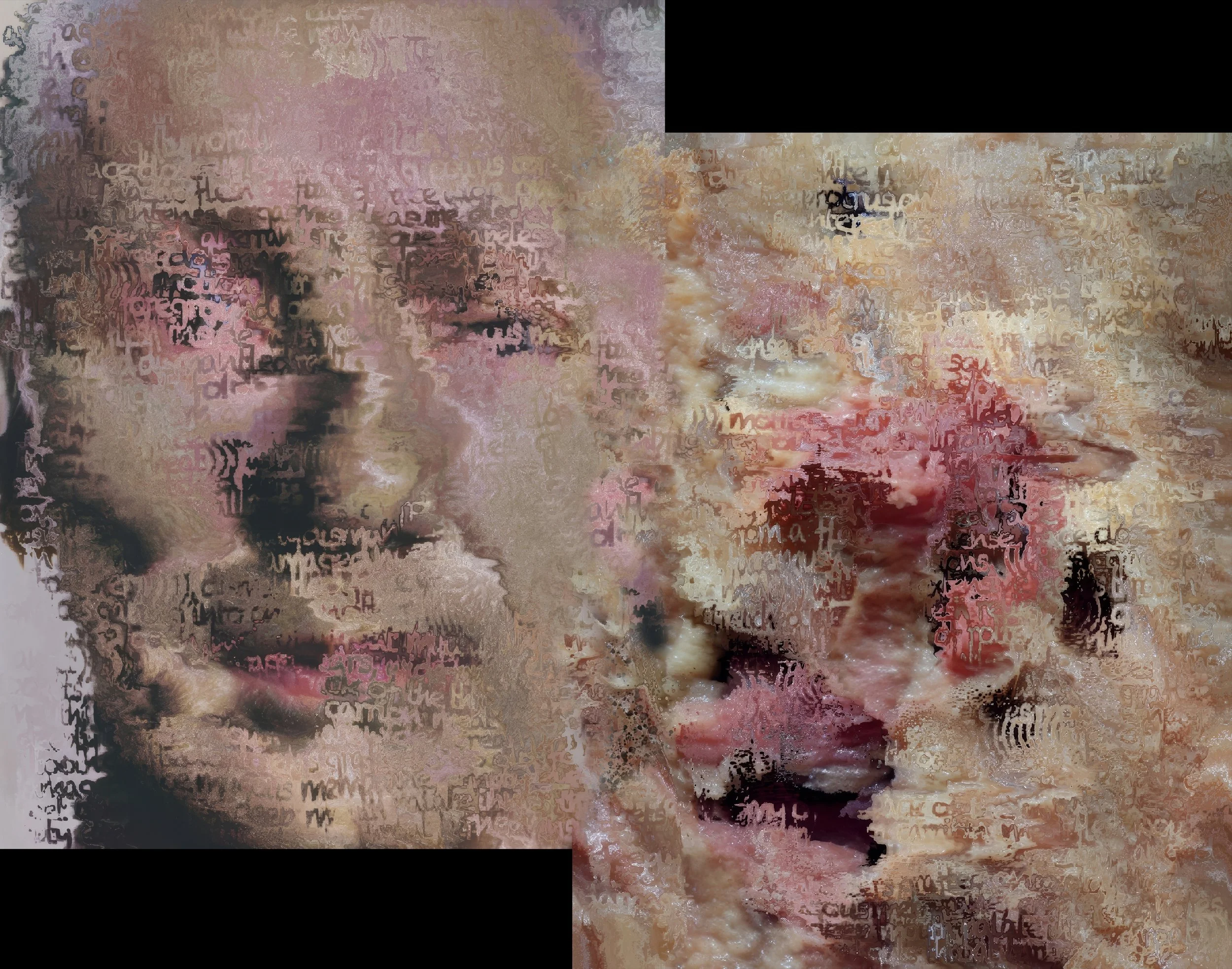
Neurodéfigurations
2024-2025
Les grands modèles d’IA texte-image tendent à uniformiser les contenus générés, en reconduisant notamment des stéréotypes préjudiciables issus des régularités statistiques apprises lors de leur entraînement, sans que les praticien·ne·s puissent réellement les contourner par le simple usage des prompts.
Face à ce constat, ce projet réunit deux vidéos, Wh!te (2024) et Neural Breakdowns (2025), issues de ma démarche de recherche-création plus largement consacrée au bricolage critique d’un modèle d’IA texte-image en particulier : Stable Diffusion. J’y explore ce que je nomme des pipelines anti-normatifs. C’est-à-dire des chaînes de modules algorithmiques, assemblées dans des interfaces graphiques, qui détournent les usages standard de ce modèle, questionnent ses potentiels inexplorés, et confrontent ses biais encodés.
En concevant ces pipelines, j’automatise largement la génération de prompts et d’images. Cette mise en retrait volontaire de mon influence permet de mieux révéler les tendances stéréotypiques de Stable Diffusion lorsqu’il fonctionne en autonomie. Simultanément, elle me pousse à me placer dans une posture d’utilisateur perturbateur tentant de déjouer cette tendance en opérant, non plus sur ce que je souhaiterais représenté via les prompts, mais en intervenant directement sur l’infrastructure algorithmique : modulation fine du processus de débruitage, pondérations volontairement aberrantes des termes du prompt pour provoquer des altérations locales de l’image, ajout de modules qui intensifient une esthétique du glitch.
L'objectif est alors de déplacer le mode d’usage de ces IA vers un travail à la fois critique et créatif qui rend visible l’infrastructure de l’IA et les possibilités de défigurer les stéréotypes avec elle.
2024
Vidéo (mp4).
4320 × 5464 px.
1 min 30 s
Génération d’images avec Stable Diffusion via Automatic1111. Animation et composition sous Max/MSP/Jitter.
Présentation en diptyque avec Neural Breakdowns, projection côte à côte, lecture en boucle.
Wh!te
Wh!te (2024) a été réalisé avec Automatic1111 (un programme à code source ouvert basé sur Stable Diffusion) et Max/MSP/Jitter pour l’animation de la vidéo finale. Partant d’une invite destinée à sonder ce que Stable Diffusion associe à « un homme ordinaire », les premières sorties n’ont produit que des portraits d’hommes blancs d’âge mûr. À partir de l’un d’eux, j’ai engagé un protocole récursif : chaque image génère une nouvelle invite, que je module en pondérant et variant certains termes pour provoquer des mutations locales et faire dériver le visage normatif vers de nouvelles alternatives aberrantes. La vidéo rend visible cette dérive contrôlée et s’accompagne de deux illustrations : (1) celle du prompt d’origine et des premières sorties biaisées, et (2) un aperçu du patch Jitter qui orchestre l'animation de la dislocation puis la reconstruction du visage.
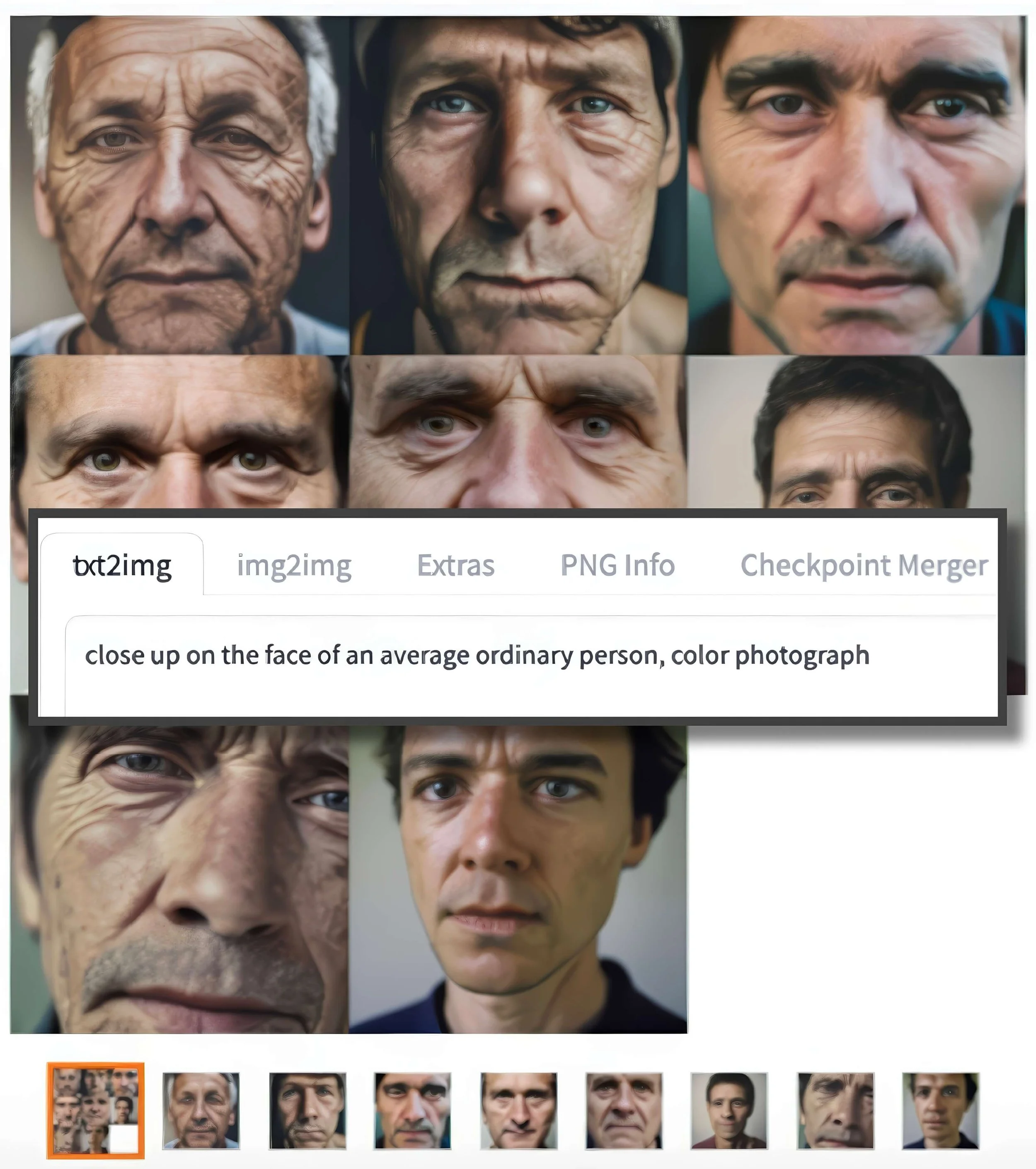
Prompt initial et premières générations d’images
Image numérique (JPEG)
3261 × 3680 px
(visuel d’accompagnement)
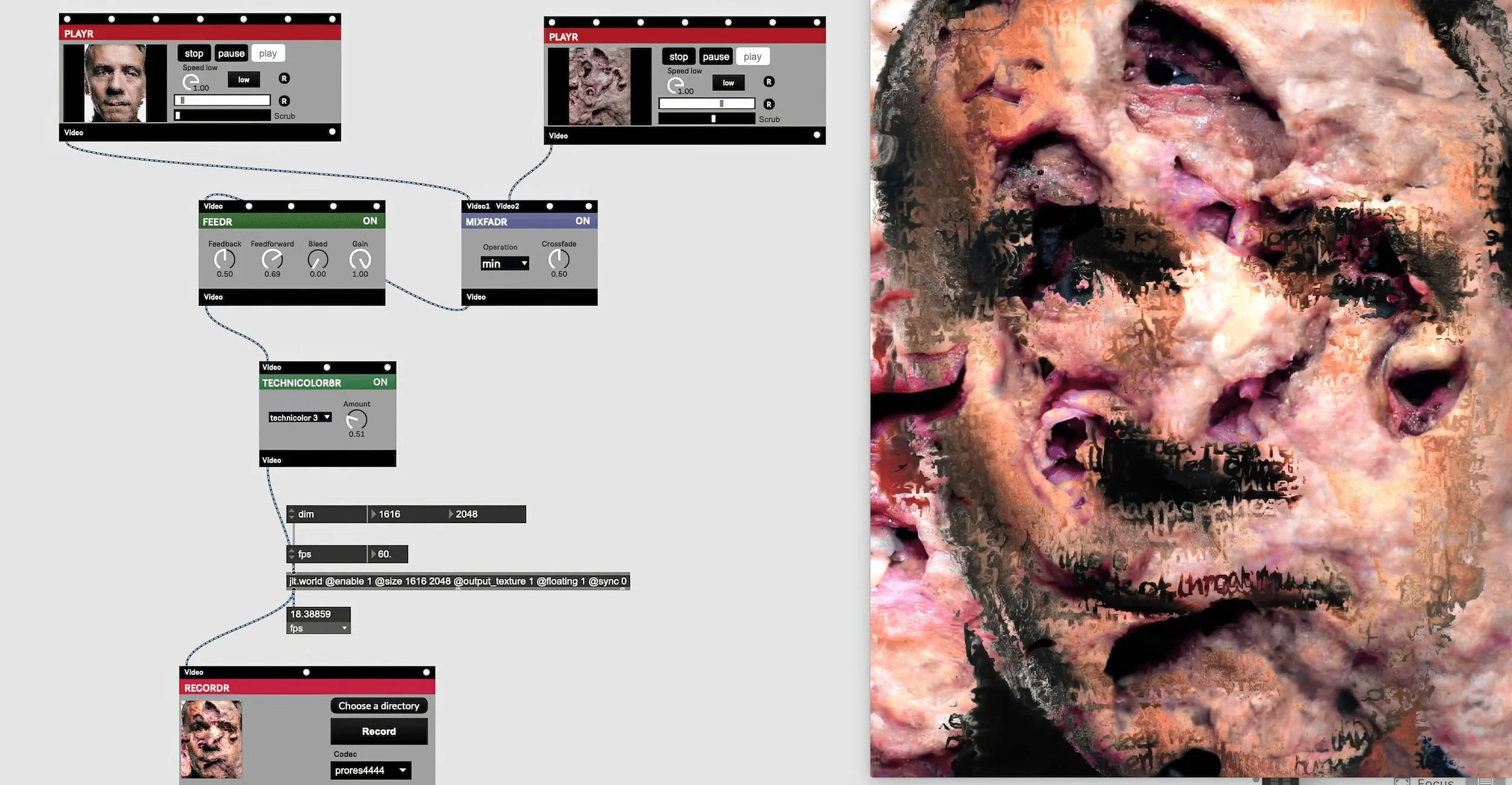
Animation des altérations subies par le visage (Patch Jitter)
Image numérique (JPEG)
3840 × 1994 px
(visuel d’accompagnement)
Neural Breakdowns (2025), est conçue sur l’interface nodale open source ComfyUI. Cette oeuvre déplace la primauté de l’invite textuelle au profit du débruitage lui-même (soit le mode de génération propre aux modèles dits de diffusion, qui part d’un bruit gaussien pour reconstruire progressivement une image). Une description fixe et stéréotypée sert d’étalon : elle suscite la génération d'un portait publicitaire et/ou de propagande, correspondant à un "visage américain parfait". Une fois l'image initiale générée, des modules de débruitage sont chaînés et déréglées de façon à amplifier leurs effets imprévisibles, tandis qu’un algorithme de classification tente d’identifier des figures dans les images de plus en plus informes que génère ce chaînage. La vidéo finale restitue cette tension frénétique entre identification et désordre et est accompagnée (1) d’un aperçu du pipeline (prompt initial et image source) ainsi que (2) d’un focus sur le module de classification.
2025
Vidéo (mp4).
4096 × 4096 px.
1 min 30 s
Génération d’images avec Stable Diffusion via ComfyUI. Modèle classification d’images YOLO. Montage de l’animation sur Adobe Premiere Pro
Présentation en diptyque avec Wh!te, projection côte à côte, lecture en boucle.
Neural Breakdowns
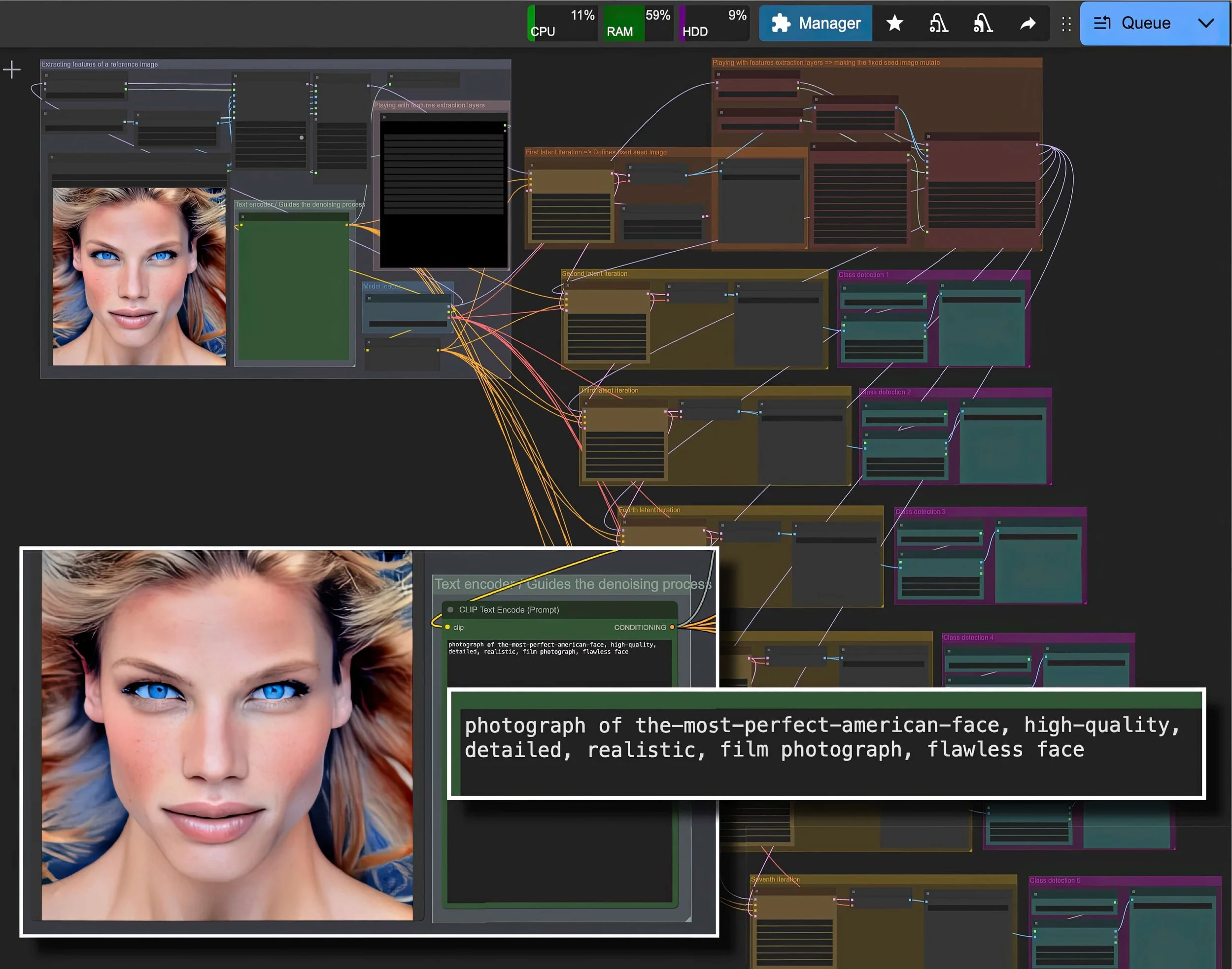
Aperçu général du pipeline, ainsi que du prompt et de l’image initiaux
Image numérique (JPEG)
3906 × 3073 px
(visuel d’accompagnement)
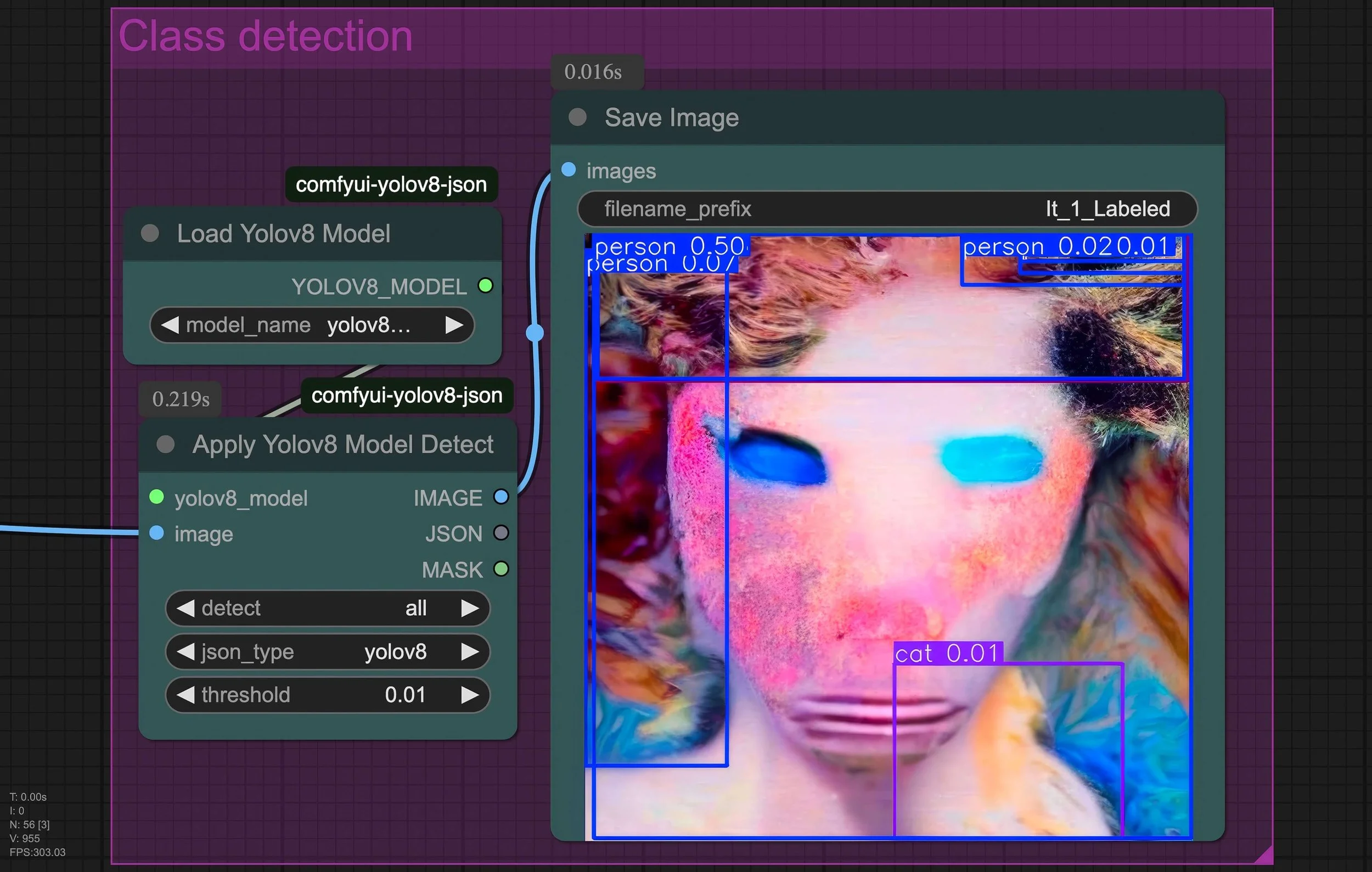
Détail d’un module tentant de détecter la probabilité de certaines figures dans l’image
Image numérique (JPEG)
4311 × 2740 px
(visuel d’accompagnement)